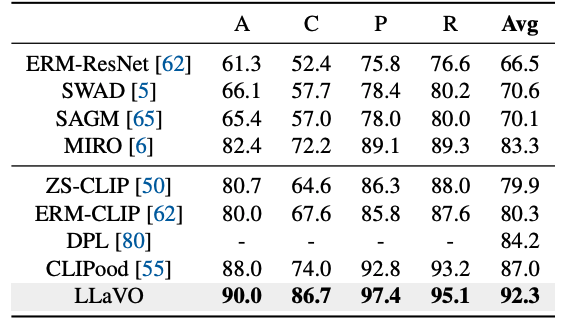
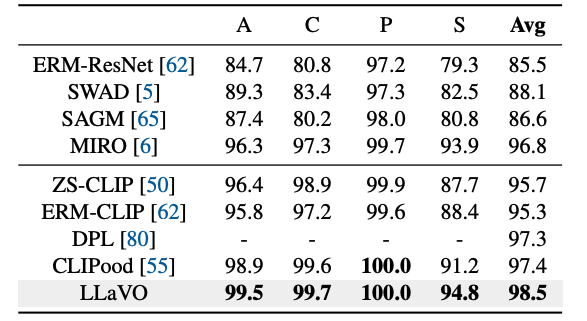
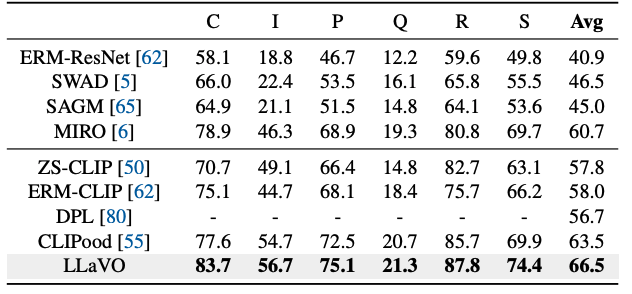
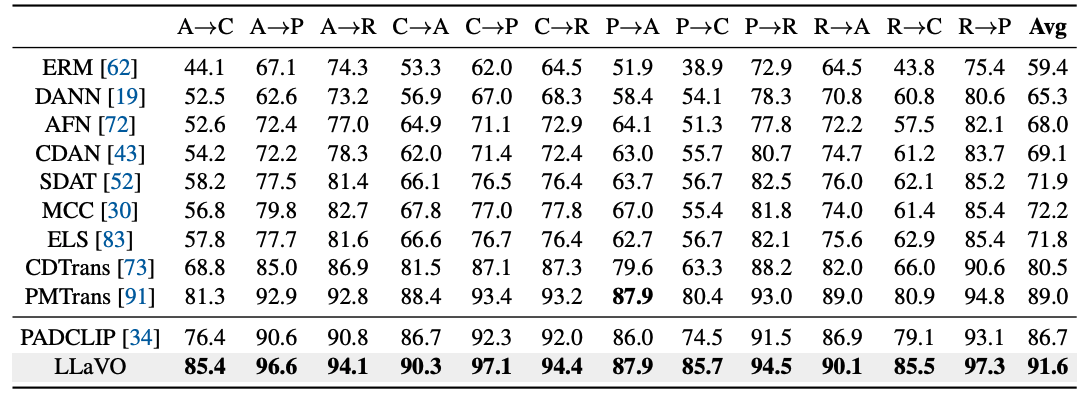
Overview

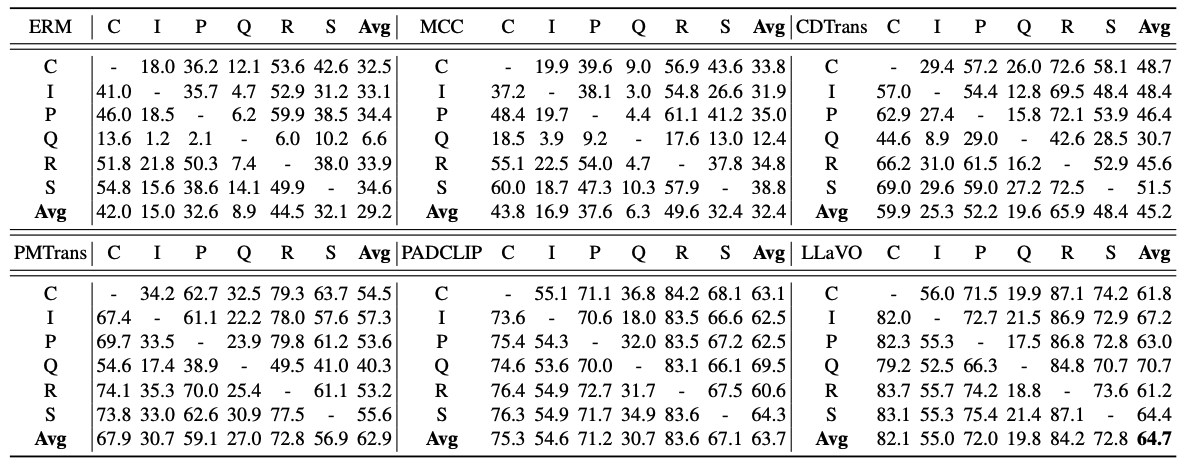
Recent advances achieved by deep learning models rely on the independent and identically distributed assumption, hindering their applications in real-world scenarios with domain shifts. To tackle this issue, cross-domain learning aims at extracting domain-invariant knowledge to reduce the domain shift between training and testing data. However, in visual cross-domain learning, traditional methods concentrate solely on the image modality, disregarding the potential benefits of incorporating the text modality. In this work, we propose VLLaVO, combining Vision language models and Large Language models as Visual cross-dOmain learners. VLLaVO uses vision-language models to convert images into detailed textual descriptions. A large language model is then finetuned on textual descriptions of the source/target domain generated by a designed instruction template. Extensive experimental results under domain generalization and unsupervised domain adaptation settings demonstrate the effectiveness of the proposed method.